LRU 缓存机制
题目
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制。它应该支持以下操作: 获取数据
get和 写入数据put。获取数据
get(key)- 如果密钥 (key) 存在于缓存中,则获取密钥的值(总是正数),否则返回 -1。 写入数据put(key, value)- 如果密钥不存在,则写入其数据值。当缓存容量达到上限时,它应该在写入新数据之前删除最近最少使用的数据值,从而为新的数据值留出空间。进阶:
你是否可以在 O(1) 时间复杂度内完成这两种操作?
示例:
LRUCache cache = new LRUCache( 2 /* 缓存容量 */ ); cache.put(1, 1); cache.put(2, 2); cache.get(1); // 返回 1 cache.put(3, 3); // 该操作会使得密钥 2 作废 cache.get(2); // 返回 -1 (未找到) cache.put(4, 4); // 该操作会使得密钥 1 作废 cache.get(1); // 返回 -1 (未找到) cache.get(3); // 返回 3 cache.get(4); // 返回 4
散列表和双向链表组合
一个LRU缓存需实现两个特性,一是快速按键查找值,二是将值或键按最近使用情况排序以便快速获取最近最少使用的值或键。
常用的数据结构中,散列表可以非常高效地实现「按键查找值」;双向链表可以高效地实现有序序列,同时高效地插入、移除元素。所以,我们可以组合散列表和双向链表实现LRU缓存。
举个列子,创建一个散列表和双向链表。散列表初始时为空。双向链表初始时也为空,同时维护分别指向链表头尾的两个引用。

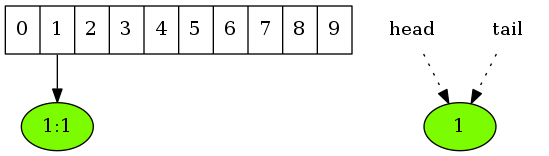
将键值对(1,1)存入缓存时,先将其存入散列表对应的桶中,再将键1加到链表的头端。
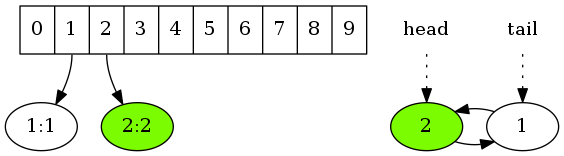
将键值对(2,2)存入缓存时,先将其存入散列表对应的桶中,再将键2加到链表的头端。
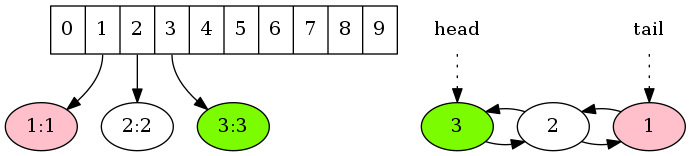
将键值对(3,3)存入缓存时,先将其存入散列表对应的桶中,再将键3加到链表的头端。若缓存的容量为2,则此时缓存中的数据已超过了容量限制。链表尾端元素即最近最少使用的元素,将其从链表中移除,同时从散列表中移除相应的元素。
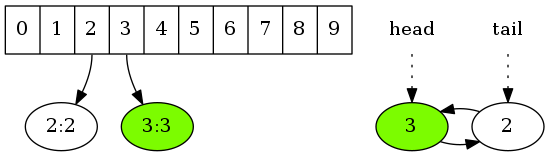
代码实现
使用JDK提供的HashMap实现散列表,再使用JDK提供的LinkedList实现双向链表。
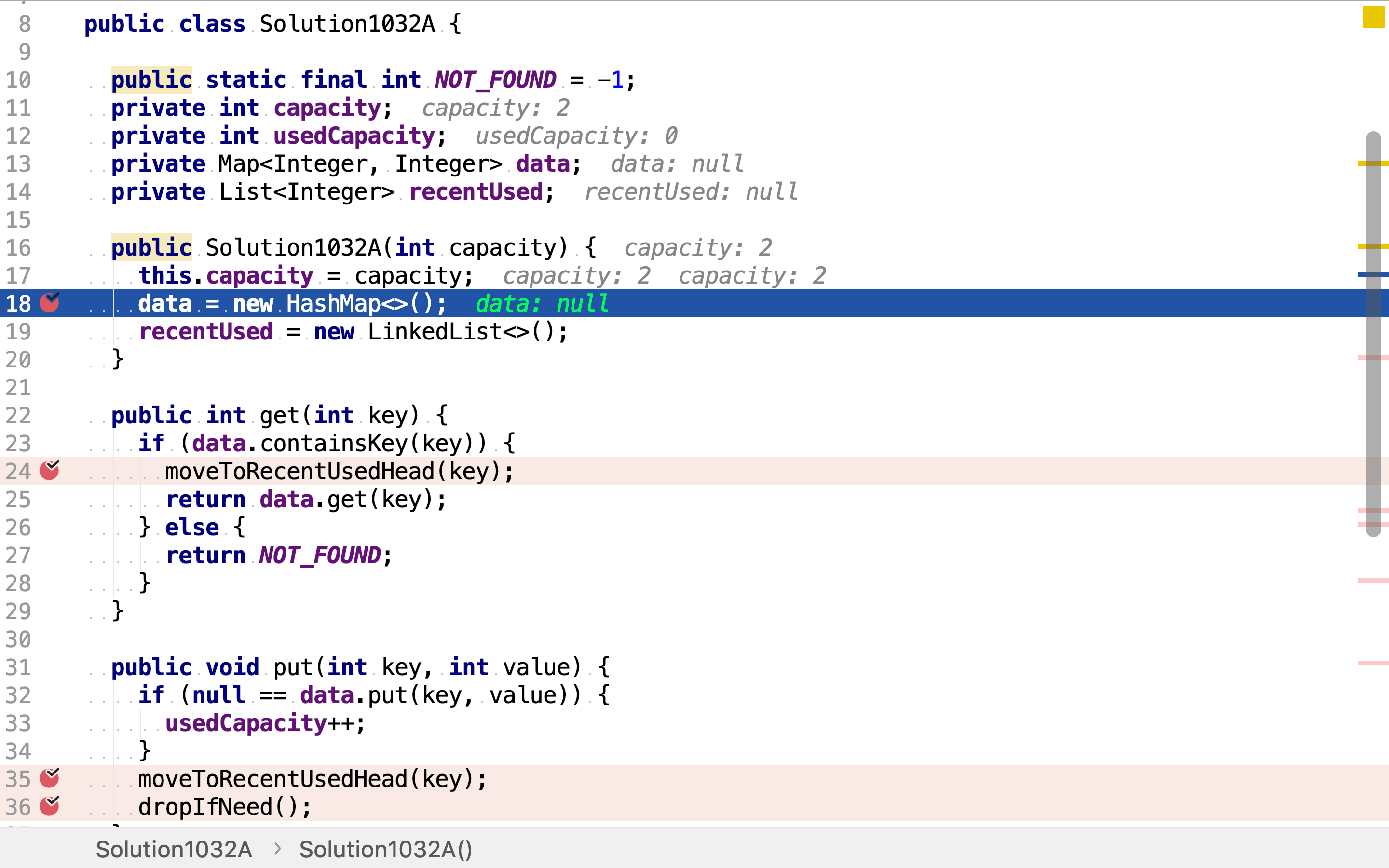
get直接以HashMap的get实现,同时将访问的键移到链表的头端。
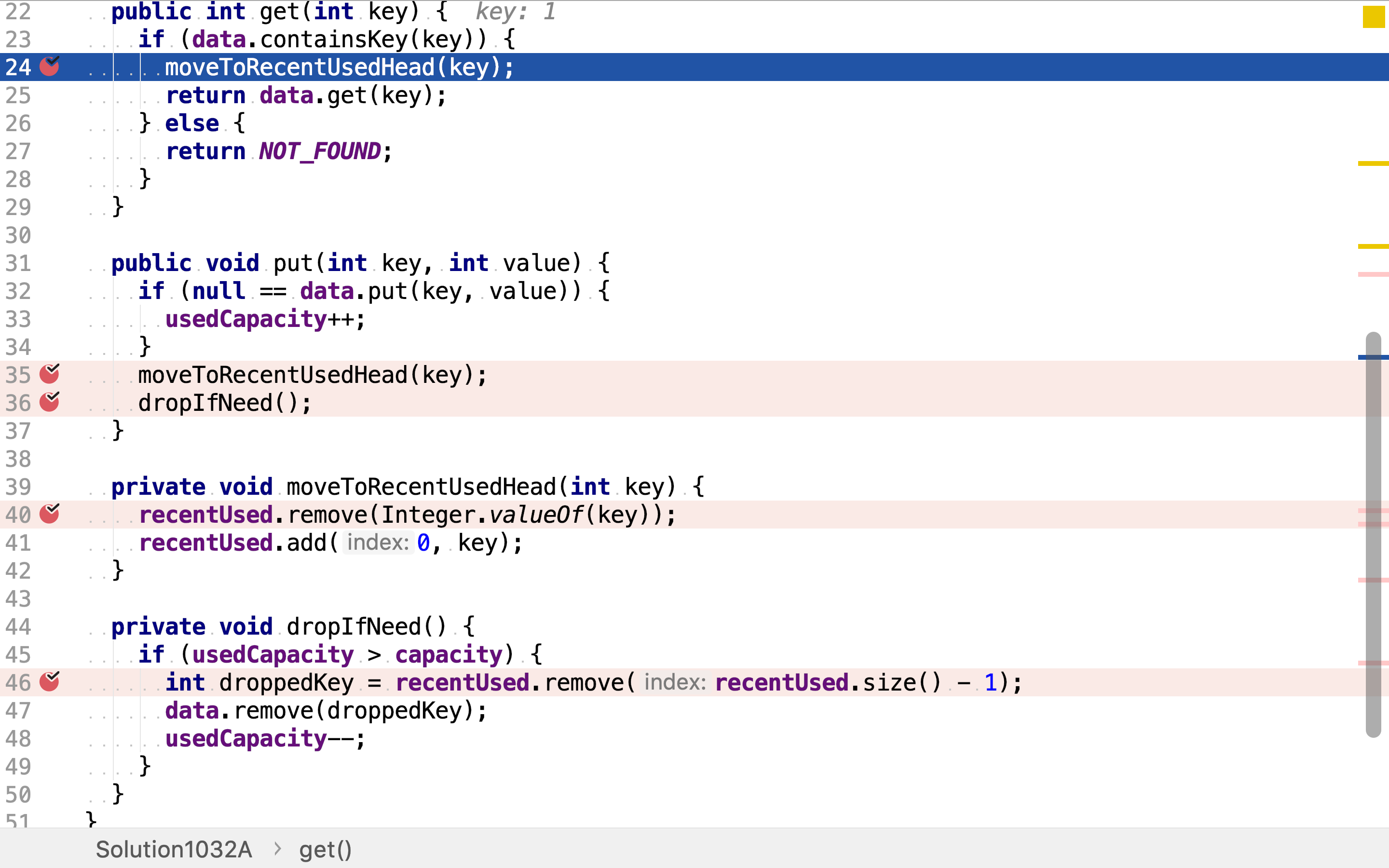
put直接调用HashMap的put,同时将出现的键移到链表的头端,若存储的元素超过了容量则将链表尾端的元素及所对应的值移除。
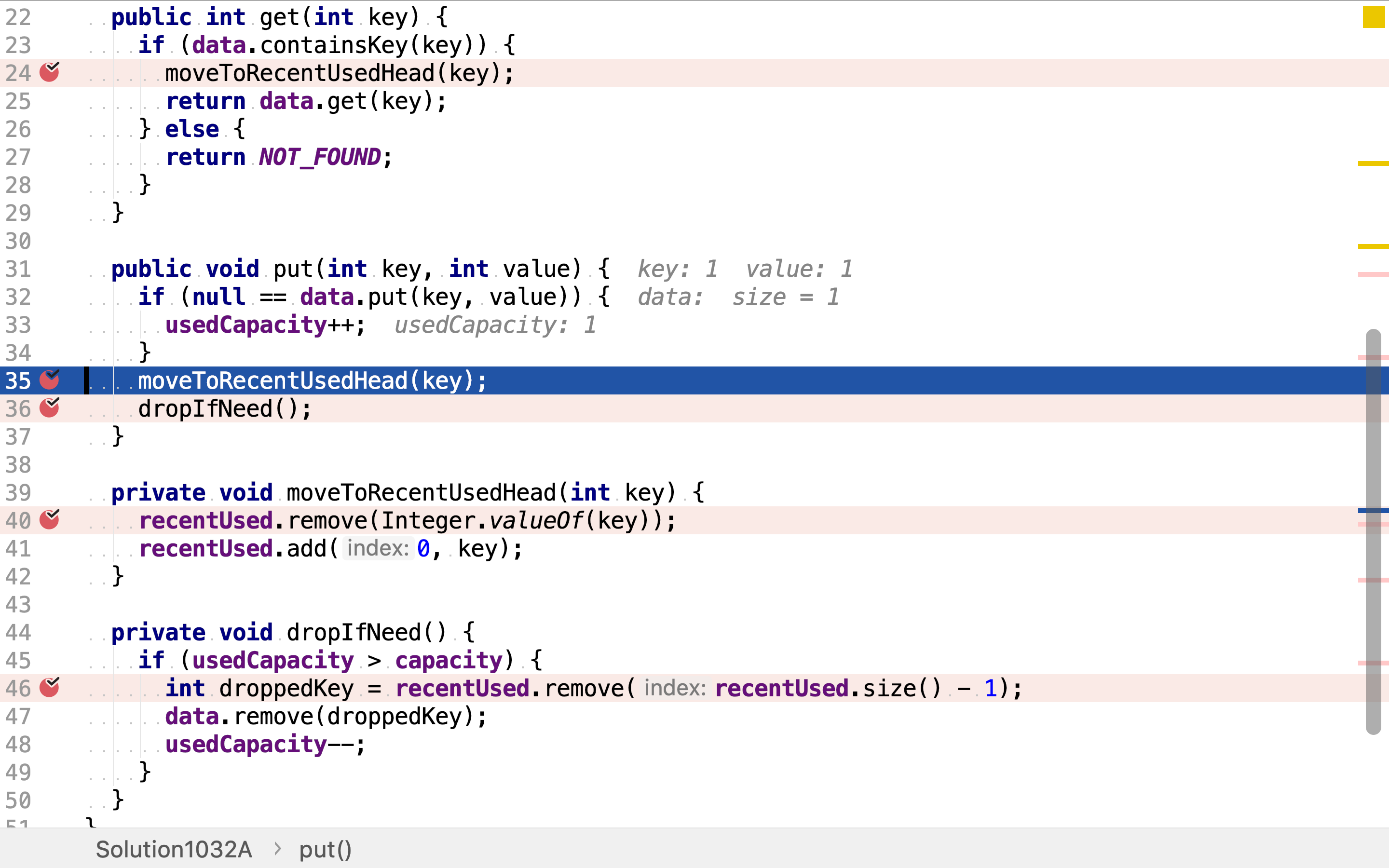
将某个值移至链表头端分为两步,先将其从原位置移除,再将其插入至头端。这两步分别使用LinkedList的remove(Object obj)和add(int index, E element)实现。
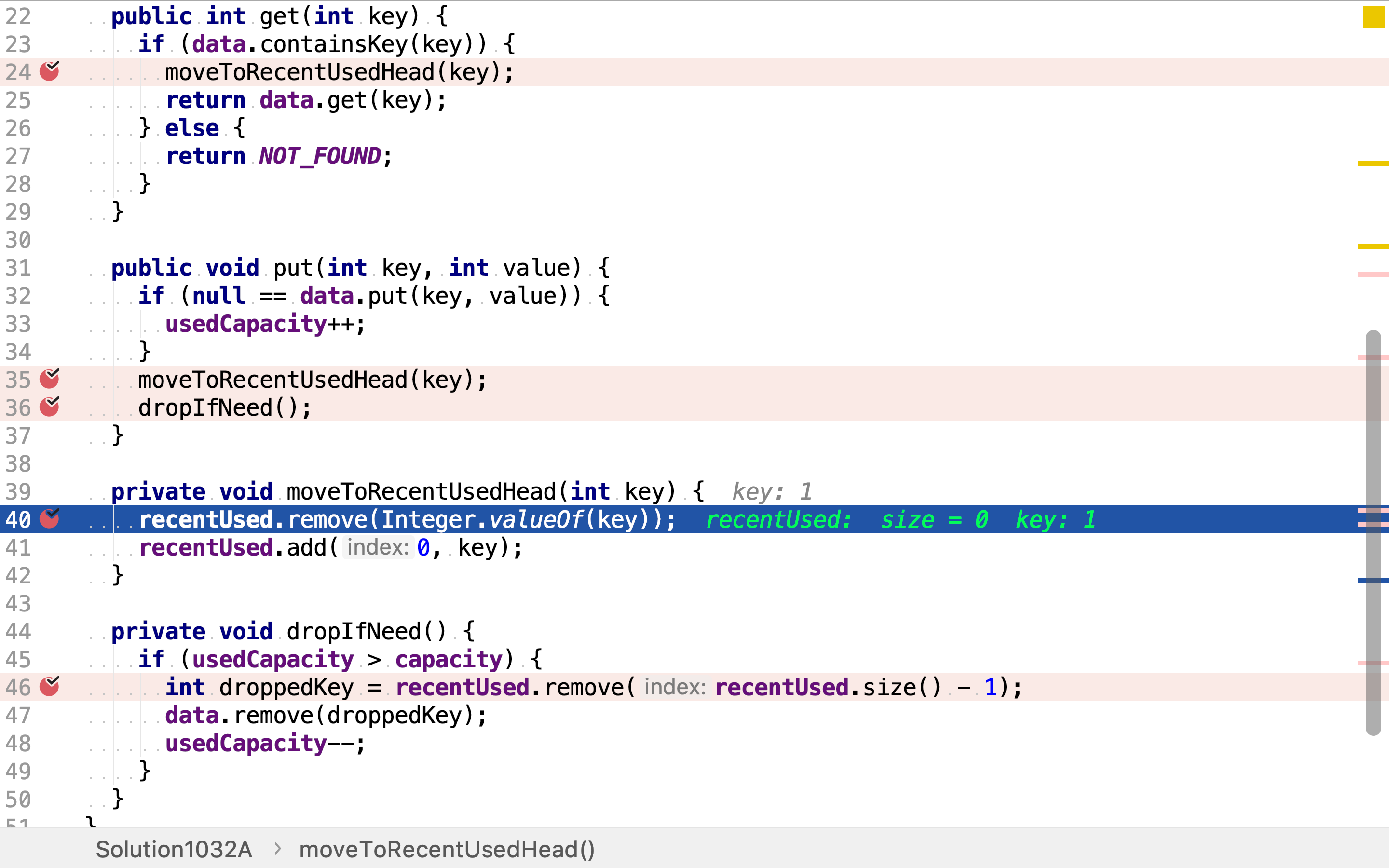
若所存元素超过了容量限制,则需移除元素。链表尾端元素即最近最少使用元素,将其移除,同时从散列表中移除其所对应的值。
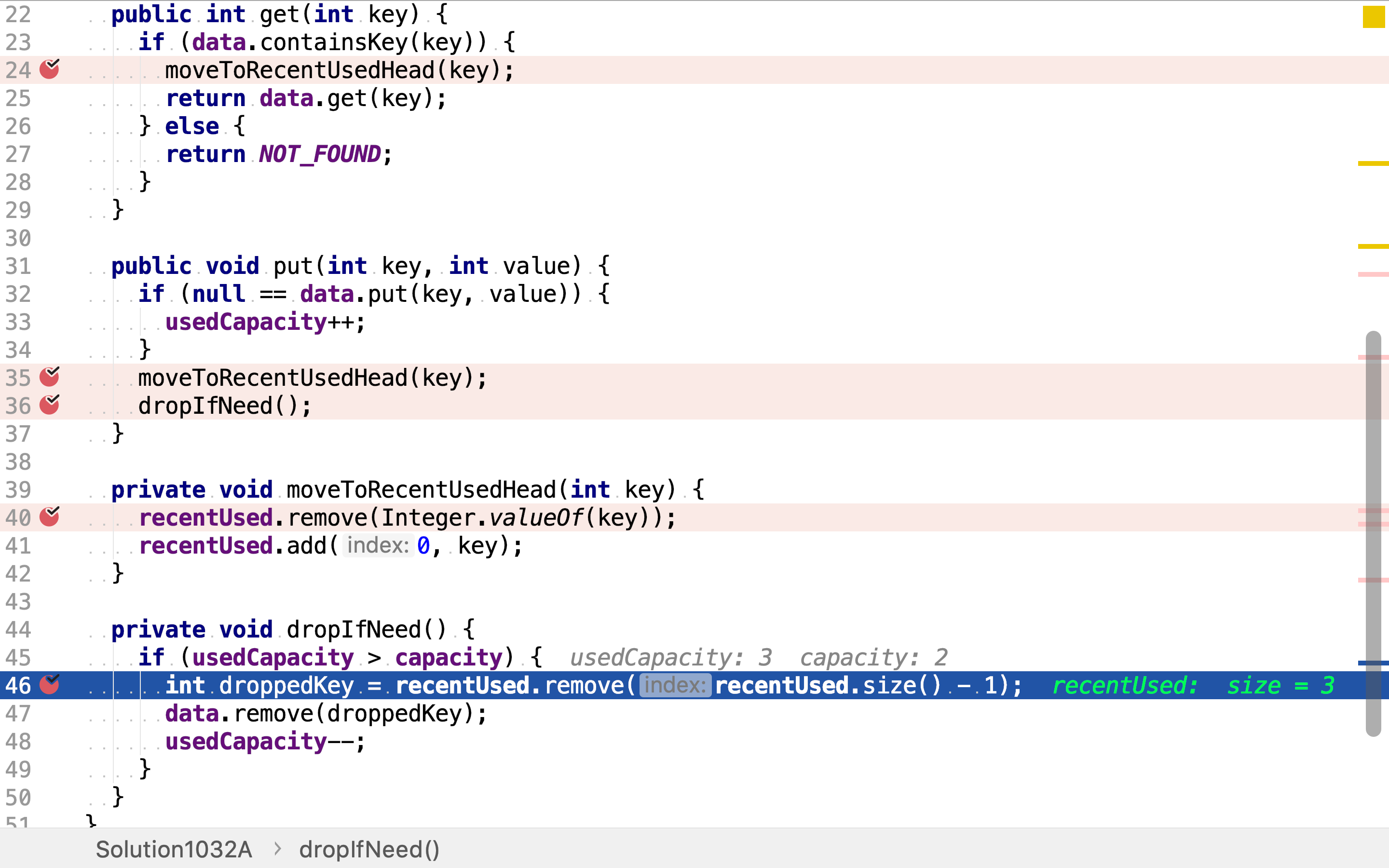
复杂度分析
时间复杂度
get操作分别调用了一次HashMap.containsKey, HashMap.get和moveToRecentUsedHead。HashMap.containsKey和HashMap.get都是常数复杂度操作。moveToRecentUsedHead需要遍历双向链表以找到目标元素再将其插至头端,其时间复杂度为。get整体时间复杂度为。
put操作分别调用了一次HashMap.put, moveToRecentUsedHead和dropIfNeed。HashMap.put是常数复杂度操作。moveToRecentUsedHead经上述分析其时间复杂度为。dropIfNeed分别调用了一次LinkedList.remove(int index)和HashMap.remove(K key),它们都是常数复杂度操作。所以put操作时间复杂度为。
空间复杂度
本实现使用了一个HashMap和一个LinkedList。假设数据量(即缓存容量)为,则空间复杂度为。
多重引用
上面的数据结构由两个独立的散列表和双向链要组成,更新链表时需要遍历整个链表找到目标元素再将其移至头部。若只保存一份元素素,前列表和双向链表都仅保存指向同一份元素的引用﹕则从散列表中读取元素时,即同时获得了其在双向链表中的位置。
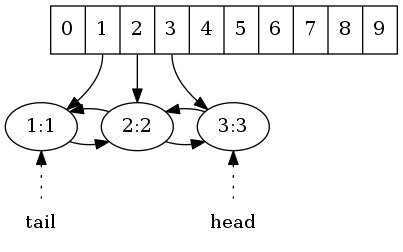
举个例子,按顺序写入三个键值对1:1, 2:2, 3:3。三个键值分别存于散列表对应位置,同时每个键值对节点持有前向、后向引用,分别指向双向链表中的前向和后向节点。
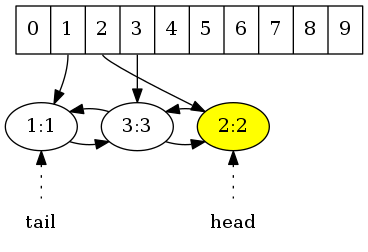
此时若get(2),则先从散列表中直接访问键值对2:2,然后将其移到双向链表的头部。因为散列表和双向链表引用的是同一个节点,所以无需遍历链表就可以获得其在双向链表中的节点。而将双向链表中已知节点移到头部仅而已变自身其前后节点的前向、后向引用。
代码实现
定义双向链表节点,该节点除了保存值外,而保存了前后、后向引用。散列表data是以整数为键,双向链表节点为值的散列表,这𥚃使用JDK提供的HashMap实现。同时,创建双向链表的头、尾引用。
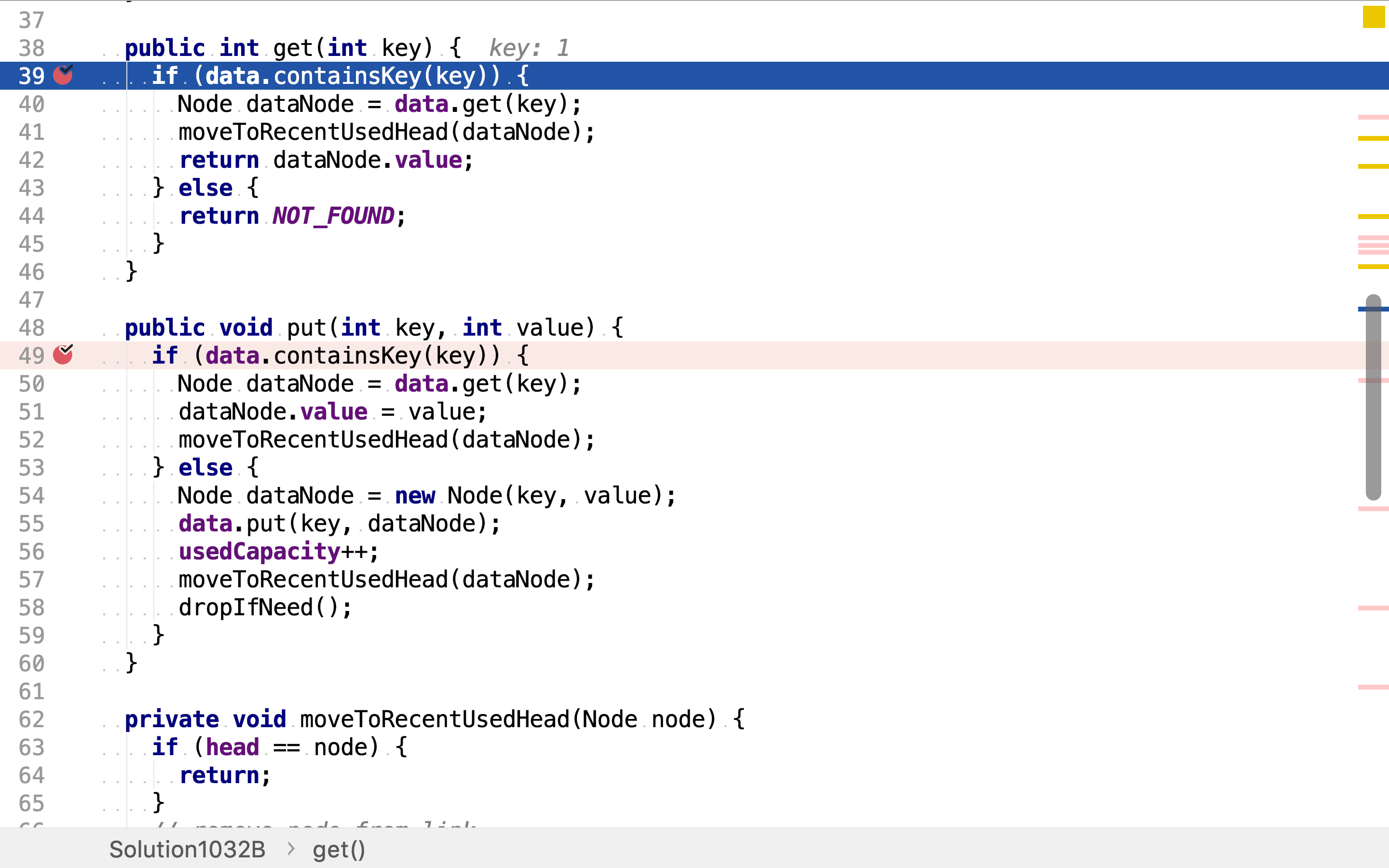
get先从散列表中按值获取节点及从节点中读取值,再将该节点移到最近最少使用双向链表的头部。
put与get类似,若散列表已持有该键,则put为更新。先从散列表中按键读取节点,再将新值更新进节点,再将该节点移到最近最少使用双向链表头部。
若前列表未持有詤键,则put为插入。先以键值对构造一个新的节点,再将新节点插入散列表,再一女月木戈新节点插入至最近最少使用双向链表头部。

将一个节点移至双向链表头部分两步,先将其从原位置移除,再将其插入头部。
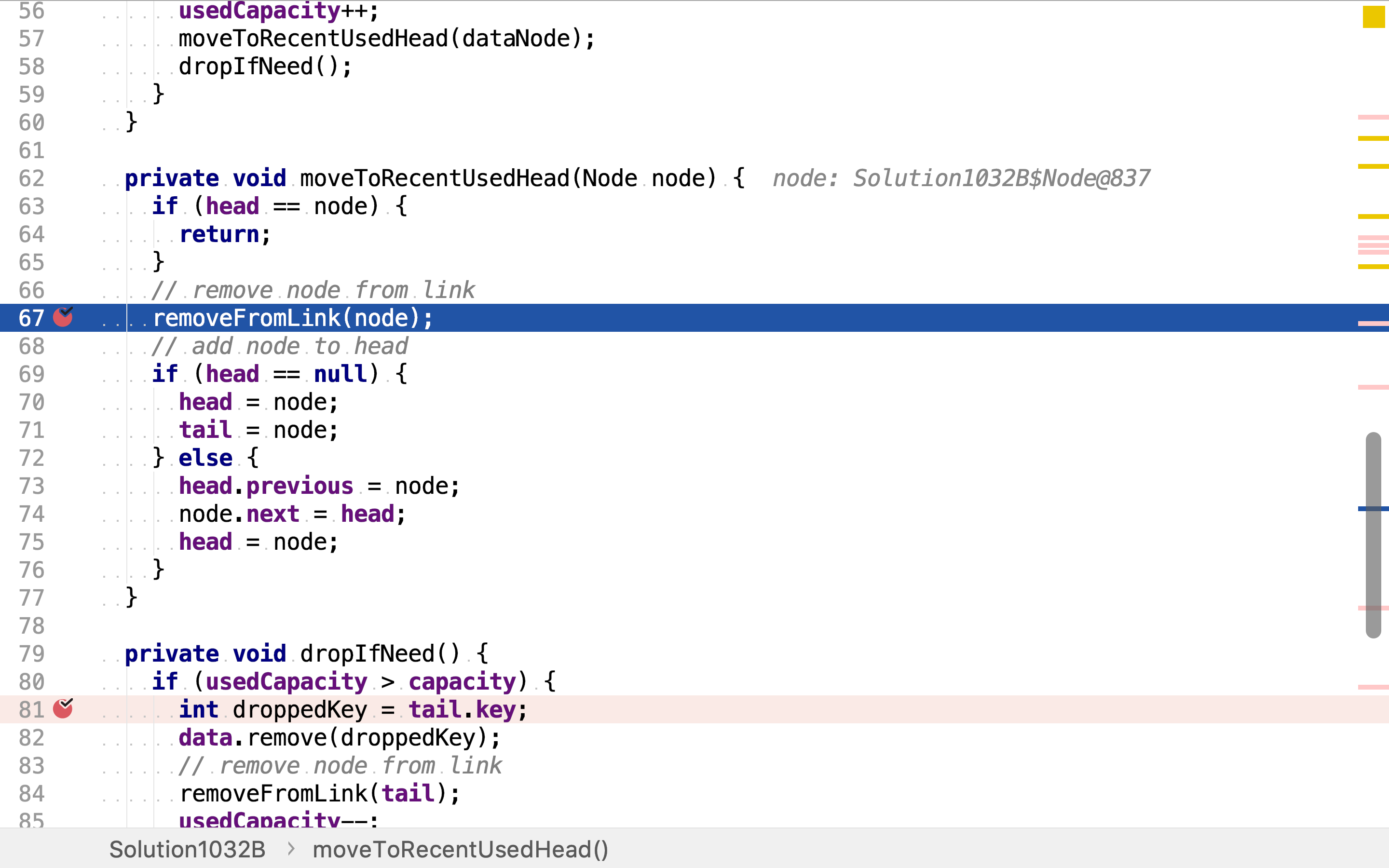
将一个节点从双向链表中移除:
- 将前向节点的后向引用指向自身的后向节点
- 将后向节点的前向引用指向自身的前向节点
- 若自身是头部节点,则将头部节点指向自身后向节点
- 若自身是尾部节点,则将尾部节点指向自身前向节点
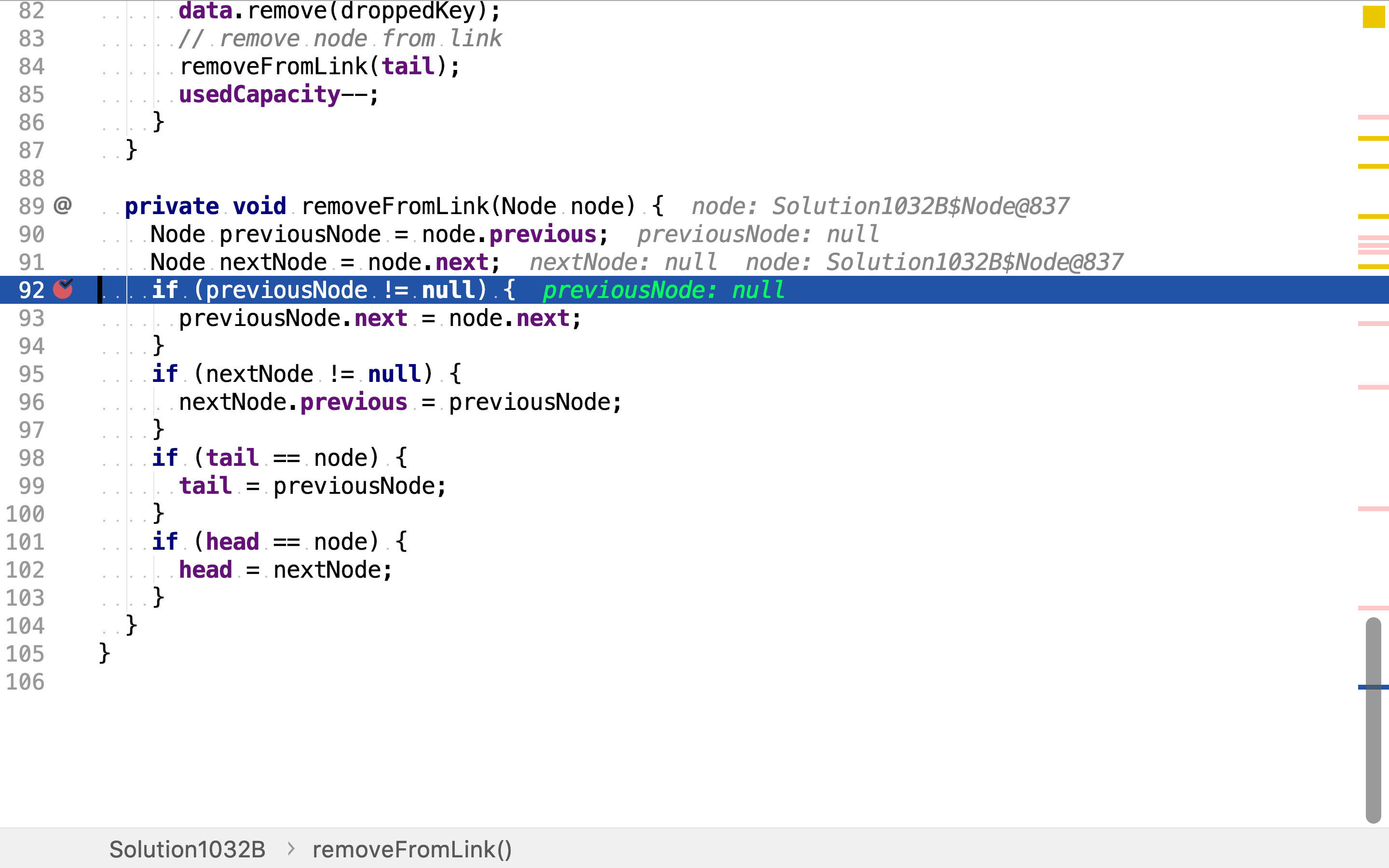
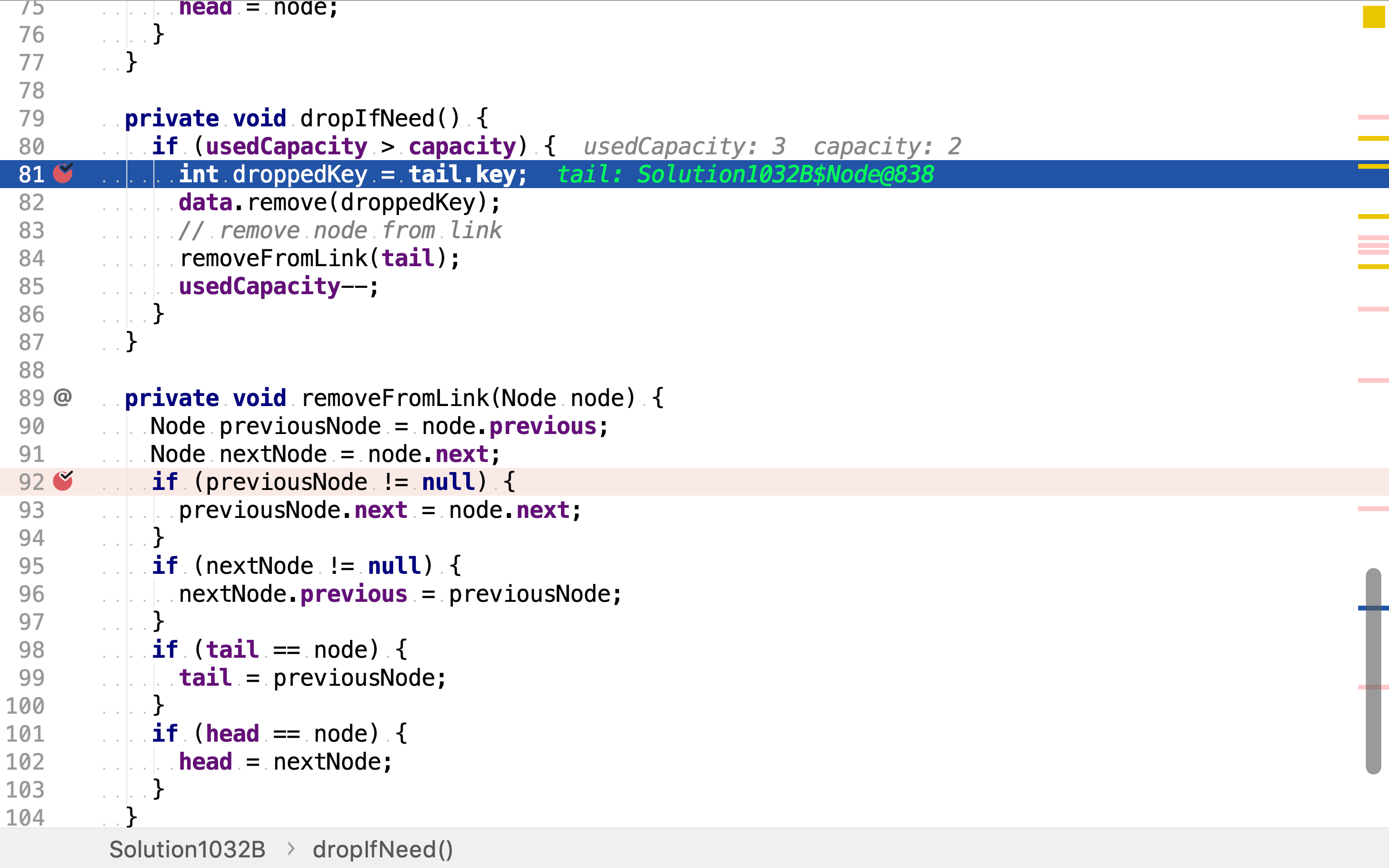
当LRU存储的数据超过容量时,要移除最近最少使用的元素。最近最少使用双向链表的尾部节点即是最近最少使用元素。先将前从散列表中移除,再从最近最少使用双向链表中移除。
复杂度分析
时间复杂度
get调用了HashMap.containsKey, HashMap.get(K k)和moveToRecentUsedHead。HashMap.containsKey和HashMap.get(K k)都是常数复杂度操作,moveToRecentUsedHead最多更改7个节点引用。所以,整体时间复杂度为。
put调用了HashMap.containsKey, HashMap.put, moveToRecentUsedHead和dropIfNeed。HashMap.containsKey和HashMap.put都是常数复杂度操作。moveToRecentUsedHead也是常数复杂度操作。dropIfNeed调用了HashMap.remove和removeFromLink,HashMap.remove是常数复杂度操作,而removeFromLink最多更改四个节点引用值。所以,整体时间复杂度为。
空间复杂度
假设键值对数据量为,则data持有个节点,每个节点持有一个元素和两个节点引用。空间复复杂度为: