P112: Decode a run-length encoded list
解码游程编码的列表。游程编码是一种数据压缩方法,其将连续重复的元素编码为[N,E]项,E是元素值,N是元素E连续重复出现的次数。当N为1时,[N, E]则简化为E。比如,给定列表[1, 1, 2, 3, 3, 3, 4],按游程编码为[[2, 1], 2, [3, 3], 4]。现在要解码被游程编码的列表。比如,当给定列表[[2, 1], 2, [3, 3], 4]时,应返回[1, 1, 2, 3, 3, 3, 4]。
依旧是先写测试用例:
from python99.lists.p112 import decode
def test_decode():
assert decode([1, [3, 2], [2, 3], 4, [2, 5]]) == [1, 2, 2, 2, 3, 3, 4, 5, 5]
assert decode([1, 2, 3]) == [1, 2, 3]
assert decode([[3, 1], [2, 2], [4, 3]]) == [1, 1, 1, 2, 2, 3, 3, 3, 3]
游程编码的列表可以被递归拆分为单个元素和剩余列表,剩余列表可以被持续拆分直至为空。每一个单独元素祇可能是[N, E]项和标量值中的一个。
解码单个[N, E]项很简单,在List comprehension和 Python内建函数range的帮助下很容易实现。List comprehension的形式为:
[f(x) for x in l]
在本例中,f是常值函数(constant function),其值永远是E。结果列表的长度等于l的长度即N。 Python内建的range可以用来构造指定长度的序列。range可接受三个参数:
start起始值,默认0。生成的序列中包含起始值。stop结束值,生成的序列中不包含结束值。step步长,默认1。
当给定一个[N, E]项时,可用以下表达式解码:
[E for i in range(0,N)]
将每个单独[N, E]被解码后的列表拼接起来,就是最终结果了。
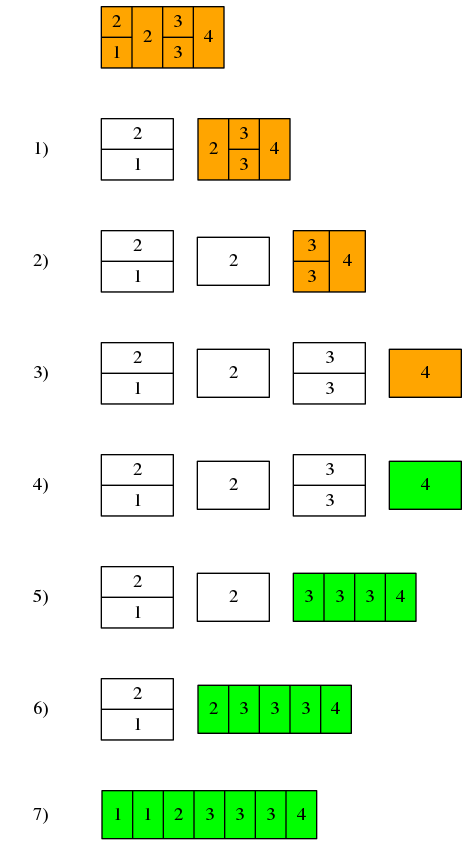
举个例子,给定编码后的列表[[2, 1], 2, [3, 3], 4]:
- 将列表
[[2, 1], 2, [3, 3], 4]拆分为头元素[2, 1]和剩余列表[2, [3, 3], 4] - 将列表
[2, [3, 3], 4]拆分为头元素2和剩余列表[[3, 3], 4] - 将列表
[[3, 3], 4]拆分为头元素[3, 3]和剩余列表[4] - 剩余列表
[4]中仅包含一个元素4,直接解码为[4] - 这一层拆分为出来的头元素是
[3, 3],解码为[3, 3, 3],再和已解码的剩余列表拼接成[3, 3, 3, 4] - 这一层拆分出来的头元素是
2,直接解码为[2],再和已解码的剩余列表拼接成[2, 3, 3, 3, 4] - 这一层拆分出来的头元素是
[2, 1],解码为[1, 1],和已解码的剩余列表拼接成最终结果[1, 1, 2, 3, 3, 3, 4]
代码实现:
# Decode a run-length encoded list.
# Given a run-length code list generated as specified in problem 1.11.
# Construct its uncompressed version
from python99.lists.p107 import flatten
def decode(l):
if l is None:
return []
if len(l) == 0:
return []
return decode_term(l[0]) + decode(l[1:])
def decode_term(term):
if isinstance(term, list):
return [term[1] for e in range(0, term[0])]
else:
return [term]