P108: Eliminate consecutive duplicates of list elements
去除连续重复的元素。 好习惯是先写测试再写实现:
from python99.lists.p108 import compress
def test_compress():
assert compress(None) == []
assert compress([]) == []
assert compress([1]) == [1]
assert compress([1, 1, 2, 3, 4, 4, 5, 6, 6, 6, 6]) == [1, 2, 3, 4, 5, 6]
assert compress([2, 3]) == [2, 3]
从列表中去除连续重复元素好像有点难...
没有什么问题是递归解决不了的!
假设已经拥有了一个方法可以去除列表中所有连续重复的元素。任意列表都可以被拆分为第一个元素和剩余列表。当剩余列表已是去除「连续重复元素」的列表,且第一个元素跟剩余列表中第一个元素不相同,则合併第一个元素和剩余列表得到的列表也是不包含「连续重复元素」的列表。 反过来,从构造无连续重复元素列表的⻆度思考,似乎更容易理解。一开始,列表中仅有一个元素。然后将一个新的元素和列表拼接在一起。如果新元素和列表中第一个元素相同,则其是一个「连续重复」的元素,应该直接消掉。假如每次将新元素拼接进列表时,都检查是不是与列表头元素相同,则可保证最终得到的列表是一个不包含连续重复元素的列表。
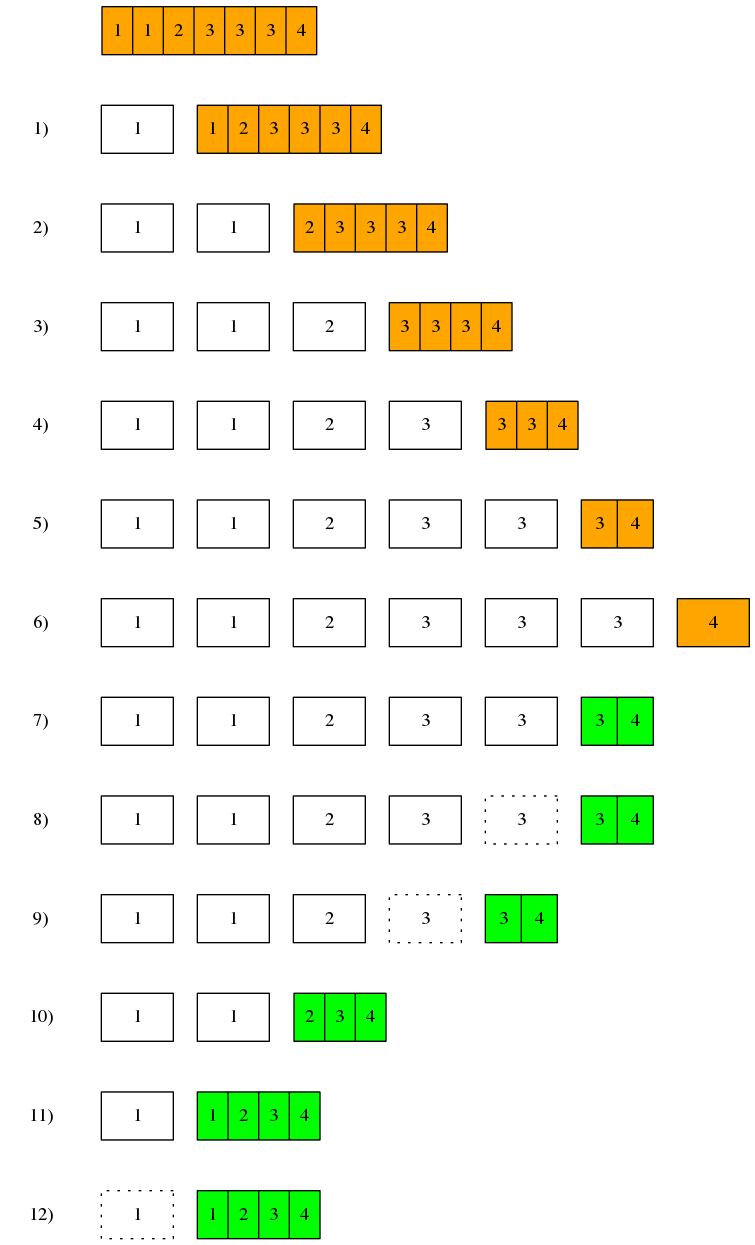
举个例子,给定列表[1, 1, 2, 3, 3, 3, 4]:
- 将列表
[1, 1, 2, 3, 3, 3, 4]拆分为1和剩余列表[1, 2, 3, 3, 3, 4],去除剩余列表中的「连续重复元素」 - 将列表
[1, 2, 3, 3, 3, 4]拆分为1和剩余列表[2, 3, 3, 3, 4],继续去除剩余列表中的「连续重复元素」 - 将列表
[2, 3, 3, 3, 4]拆分为2和剩余列表[3, 3, 3, 4],继续去除剩余列表中的「连续重复元素」 - 将列表
[3, 3, 3, 4]拆分为3和剩余列表[3, 3, 4],继续去除剩余列表中的「连续重复元素」 - 将列表
[3, 3, 4]拆分为3和[3, 4],继续去除剩余列表中的「连续重复元素」 - 将列表
[3, 4]拆分为3和[4],剩余列表仅包含一个元素,所以其肯定不包含「连续重复元素」 - 比较元素
3和剩余列表[4]中第一个元素,其不相等,可以将3和[4]拼接为[3, 4] - 比较元素
3和剩余列表[3, 4]中的第一个元素,其相等,所以元素3应被剔除 - 比较元素
3和剩余列表[3, 4]中的第一个元素,其相等,所以元素3应被剔除 - 比较元素
2和剩余列表[3, 4]中的第一个元素,其不相等,可以将2和[3, 4]拼接为[2, 3, 4] - 比较元素
1和剩余列表[2, 3, 4]中的第一个元素,其不相等,可以将1和[2, 3, 4]拼接为[1, 2, 3, 4] - 比较元素
1和剩余列表[1, 2, 3, 4]中的第一个元素,其相等,所以1应被剔除。最终得到一个不包含「连续重复元素」的列表
代码实现:
# Eliminate consecutive duplicates of list elements.
# If a list contains repeated elements they should be replaced with a single copy of the elements.
# The order of the elements should not be changed.
def compress(l):
if l is None:
return []
if len(l) == 0:
return []
if len(l) == 1:
return l
first = l[0]
remain = l[1:len(l)]
if first == remain[0]:
return compress(remain)
else:
return [first]+compress(remain)